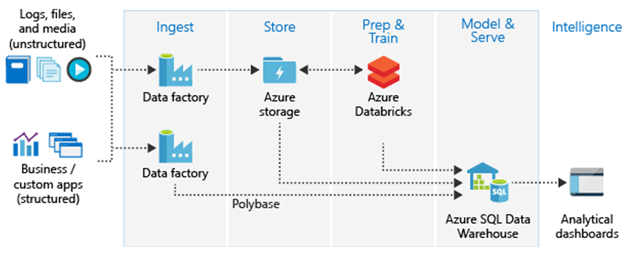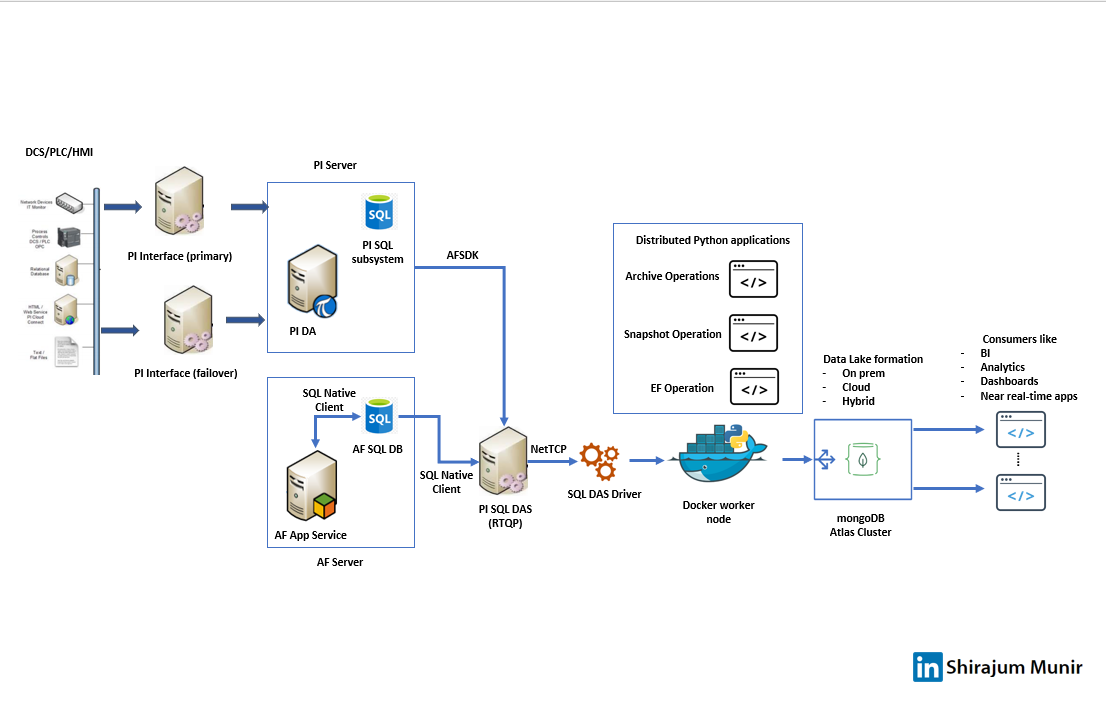
In this post, we will play around with the idea of implementing a modern data lake with good old OSISoft/AVEVA PI environment on the backend. After some poking around, I was able to implement this mongoDB based data lake. A challenge of implementing a data lake on SQL architecture is the always changing data structure. I think json based storage on mongoDB is a perfect answer to that and the reason I selected it here. Also, being able to separate docker worker nodes running python scripts based on data frequency and volume is a huge advantage.
I am being cheap and implemented this using mongoDB community cloud edition for now haha. But stay tuned to see the Atlas cluster on AWS soon. Once I have this on the cloud, I plan to expand the work a lot more on the consumer end. Plus, I might be getting some Databricks credit. If I get that, I would love to implement this on Databricks as well. Yes, I am super stoked for the Christmas break to work on all these (if you couldn’t tell already haha).
Interested to continue the conversation of implementing modern data lake with typical historians on the backend? Feel free to share your thoughts!